So ersetzen Sie alle Zeichenfolgen in einer Datei, die mit einem Präfix beginnen
Antworten:
Verwenden von sed:
sed -E 's/((^| )2:)[^ ]*/\10/g' in > out
Auch, wie inspiriert souravc Antwort , wenn es nicht eine Chance auf einen 2:Teilstring nach dem Beginn eines Strings nicht ein führendes enthält 2:String (zB gibt es nicht eine Chance auf eine 1:202:25Zeichenfolge, die der folgende Kurzbefehl ersetzen würde 1:202:0), das Befehl kann auf diesen verkürzt werden:
sed -E 's/2:[^ ]*/2:0/g' in > out
Befehl # 1 / # 2 Aufschlüsselung :
-E: lässtseddas Muster als ERE-Muster (Extended Regular Expression) interpretieren;> out: leitet weiterstdoutzuout;
sedBefehl # 1 Aufschlüsselung :
s: behauptet, eine Substitution durchzuführen/: Startet das Muster(: Startet die Erfassungsgruppe(: Startet die Gruppierung der zulässigen Zeichenfolgen^: Entspricht dem Zeilenanfang|: trennt die zweite zulässige Zeichenfolge: Entspricht einemZeichen): Beendet die Gruppierung der zulässigen Zeichenfolgen2: Entspricht einem2Zeichen:: Entspricht einem:Zeichen): Stoppt die Erfassungsgruppe[^ ]*: Entspricht einer beliebigen Anzahl von Zeichen nicht/: stoppt das Muster / startet die Ersatzzeichenfolge\1: Rückreferenz durch die erste Erfassungsgruppe ersetzt0: fügt ein0Zeichen hinzu/: stoppt die Ersatzzeichenfolge / startet die Musterflagsg: behauptet, die Ersetzung global durchzuführen, dh jedes Vorkommen des Musters in der Zeile zu ersetzen
sedBefehl # 2 Aufschlüsselung :
s: behauptet, eine Substitution durchzuführen/: Startet das Muster2: Entspricht einem2Zeichen:: Entspricht einem:Zeichen[^ ]*: Entspricht einer beliebigen Anzahl von Zeichen nicht/: stoppt das Muster / startet die Ersatzzeichenfolge2:0: fügt eine2:0Zeichenfolge hinzu/: stoppt die Ersatzzeichenfolge / startet die Musterflagsg: behauptet, die Ersetzung global durchzuführen, dh jedes Vorkommen des Musters in der Zeile zu ersetzen
Dieser eine Liner mit sed
sed -i.bkp 's/2:\([0-9]*\)\|2:\(-\)\([0-9]*\)/2:0/g' input_file
wird ersetzen global in Zeile in input_fileeine Backup - Datei mit dem Namen hält input_file.bkpim gleichen Verzeichnis.
Dies kann weiter verkürzen erweiterte reguläre Ausdrücke verwenden , wie vorgeschlagen von kos, wie
sed -ri.bkp 's/2:\-?[0-9]*/2:0/g' input_file
2:und 2:-nur die -optionale Übereinstimmung mit erweiterten regulären Ausdrücken vornehmen möchten ( -rOption); Außerdem müssen Sie nichts erfassen, da Sie nichts ersetzen:sed -ri.bkp 's/2:\-?[0-9]*/2:0/g' input_file
Ich würde eine Basisschleife verwenden awk:
$ awk '{for (i=1; i<=NF; i++) $i~/^2:/ && $i="2:0"}1' file
1:20 2:0 3:0.432 2:0 10:12
Dies durchläuft alle Felder. Immer wenn einer von ihnen mit beginnt 2:, ersetzt er alles durch 2:0. Schließlich 1steht das für True, so dass die gesamte Zeile gedruckt wird.
Verwenden von python:
#!/usr/bin/env python2
import re
with open('test_dir/unix_se.txt') as f:
for line in f:
print re.sub(r'(?:(?<=(?: 2:))|(?<=(?:^2:)))[^ ]*', '0', line).rstrip()Hier haben wir die re.subFunktion des reModuls verwendet.
re.sub()hat das Mustersub(pattern, repl, string, count=0, flags=0)Da wir die Werte innerhalb der Gruppe nicht weiter verwenden werden, haben wir die nicht erfassende Gruppennotation verwendet
(?:)(?:(?<=(?: 2:))|(?<=(?:^2:)))Verwendet den positiven Blick nach hinten mit der Breite Null, um2:zu Beginn oder gefolgt von einem Leerzeichen übereinzustimmen.[^ ]*Entspricht null oder mehr Zeichen vor dem Leerzeichen, danach2:und ersetzt sie durch0.
Hier ist ein Beispiel:
Eingang:
2:456 1:20 2:25 3:0.432 2:-17 10:12
1:20 2:25 3:0.432 2:-17 10:12 2:543 2:-78
Ausgabe:
2:0 1:20 2:0 3:0.432 2:0 10:12
1:20 2:0 3:0.432 2:0 10:12 2:0 2:0
Danke @kos für die sedVersion:
Einige kleine Modifikationen für den perlWeg:
perl -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Schreiben Sie zurück mit:
perl -i -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Erläuterung:
((^|\s)2:)[^\s]*
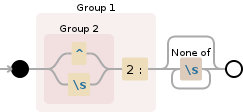
1. Erfassungsgruppe
((^|\s)2:)- 2. Erfassungsgruppe
(^|\s) 1. Alternative:
^^Position am Anfang der Zeichenfolge bestätigen2. Alternative:
\s\sEntspricht einem beliebigen Leerzeichen[\r\n\t\f ]
2:stimmt2:buchstäblich mit den Zeichen überein- 2. Erfassungsgruppe
[^\s]*stimmen mit einem einzelnen Zeichen überein, das in der folgenden Liste nicht vorhanden istQuantifizierer:
*Zwischen null und unbegrenzt, so oft wie möglich, nach Bedarf zurückgeben [gierig]\sEntspricht einem beliebigen Leerzeichen[\r\n\t\f ]
Oder mit einem positiven Lookbehind , thx @steeldriver
perl -pe 's/(?<=2:)\S*/0/g' testdata
Erläuterung
(?<=2:)\S*
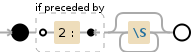
(?<=2:)Positives Aussehen - Stellen Sie sicher, dass der unten stehende reguläre Ausdruck übereinstimmen kann2:passt zu den Zeichen2: buchstäblich\S*Entspricht einem beliebigen Leerzeichen[^\r\n\t\f ]Quantifizierer:
*Zwischen null und unbegrenzt, so oft wie möglich, nach Bedarf zurückgeben [gierig]
s/(?<=2:)\S*/0/g(alle folgenden Folgen von Nicht-Leerzeichen ersetzen 2:durch 0)?
S+als S*eine leere Zeichenfolge zu ersetzen, 2:dh 2:wird 2:0, was möglicherweise nicht das beabsichtigte Verhalten ist
2:genau passenden Strings ? Sollten diese ersetzt werden?