In ihrer Arbeit über Autoencoder für die Textklassifizierung demonstrierten Hinton und Salakhutdinov die Darstellung der zweidimensionalen LSA (die eng mit PCA verwandt ist) : 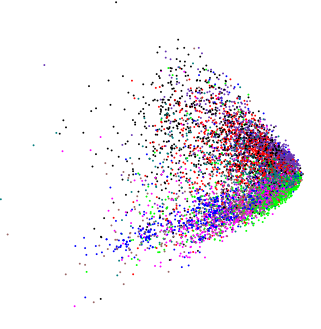 .
.
Durch Anwenden von PCA auf absolut unterschiedliche, leicht hochdimensionale Daten erhielt ich ein ähnlich aussehendes Diagramm:  (außer in diesem Fall wollte ich wirklich wissen, ob es eine interne Struktur gibt).
(außer in diesem Fall wollte ich wirklich wissen, ob es eine interne Struktur gibt).
Wenn wir zufällige Daten in PCA einspeisen, erhalten wir einen scheibenförmigen Blob, sodass diese keilförmige Form nicht zufällig ist. Bedeutet es etwas für sich?
6
Ich gehe davon aus, dass alle Variablen positiv (oder nicht negativ) und kontinuierlich sind. In diesem Fall sind die Kanten des Keils nur die Punkte, ab denen die Daten 0 / negativ werden würden. Außerdem können Sie dasselbe Muster erhalten, das Sie mit positiven Variablen mit rechtem Versatz anzeigen. Die Beobachtungen sind am unteren Ende zusammengefasst. Wenn Sie positive einheitliche Zufallsvariablen hätten, würden Sie ein (gedrehtes) Quadrat sehen. Daher sind Muster wie das von Ihnen gezeigte nur Einschränkungen für die Daten. Andere Muster können wie ein Hufeisen angezeigt werden, aber dies ist nicht auf Einschränkungen in den Bereichen der Variablen zurückzuführen.
—
Gavin Simpson
@ GavinSimpson Dies ist wesentlich mehr als ein Kommentar. Warum nicht zu einer Antwort erweitern?
—
Mike Hunter
Ich fragte meine Kinder (3 und 4 Jahre alt), woran diese Bilder sie erinnern, und sie sagten, es sei ein Fisch. Also vielleicht "fischartige Form"?
—
Amöbe
@ GavinSimpson, danke! In beiden Fällen sind Variablen in der Tat nicht negativ, aber auch in beiden Fällen sind sie ganzzahlig. Ändert das etwas?
—
Macleginn







