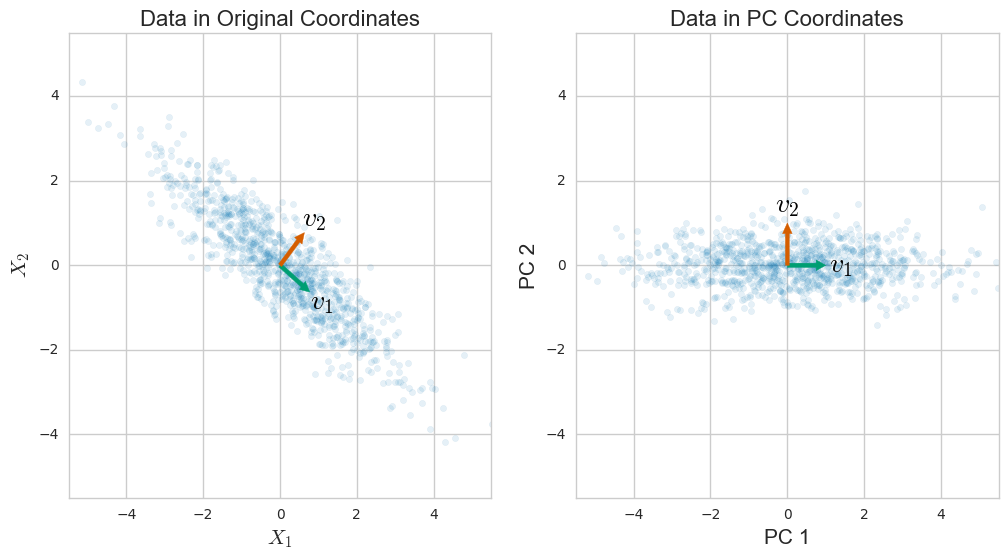
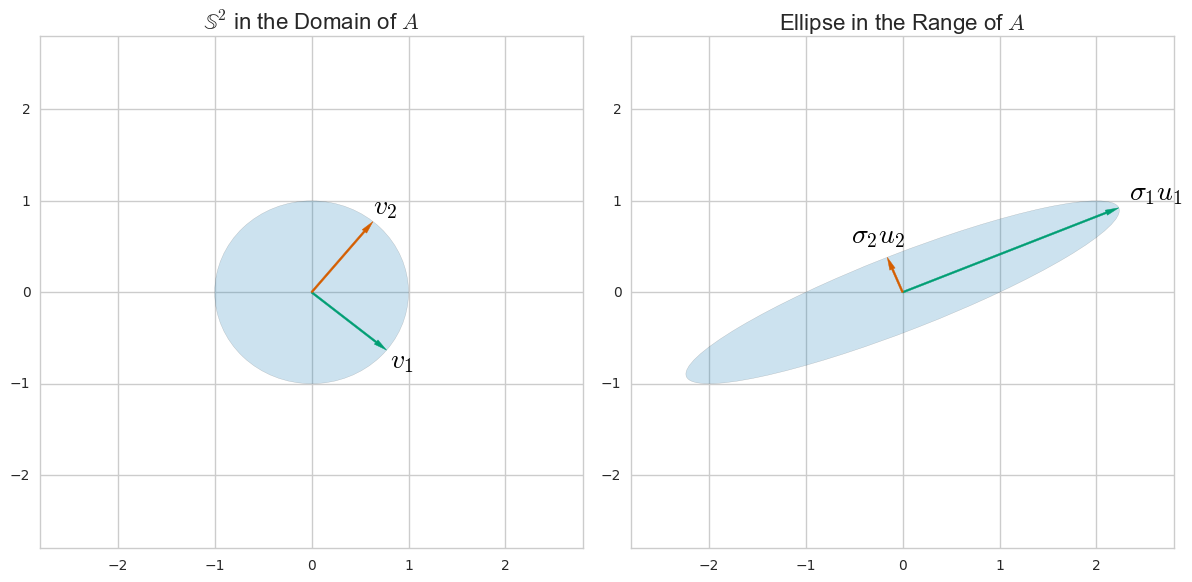
Die Hauptkomponentenanalyse (PCA) wird üblicherweise durch eine Eigenzerlegung der Kovarianzmatrix erklärt. Sie kann aber auch über die Singular Value Decomposition (SVD) der Datenmatrix . Wie funktioniert es? Welche Verbindung besteht zwischen diesen beiden Ansätzen? Wie ist die Beziehung zwischen SVD und PCA?
Oder mit anderen Worten, wie kann die SVD der Datenmatrix verwendet werden, um eine Dimensionsreduktion durchzuführen?
8
Ich habe diese Frage im FAQ-Stil zusammen mit meiner eigenen Antwort geschrieben, da sie häufig in verschiedenen Formen gestellt wird, es aber keinen kanonischen Thread gibt und es daher schwierig ist, Duplikate zu schließen. Bitte geben Sie Metakommentare in diesem begleitenden Meta-Thread an .
—
Amöbe
Zusätzlich zu einer ausgezeichneten und detaillierten Antwort von Amoeba mit ihren weiteren Links kann ich empfehlen, dies zu überprüfen , wobei PCA als Seite an Seite mit einigen anderen SVD-basierten Techniken betrachtet wird. In der dortigen Diskussion wird die Algebra fast identisch mit der Amöbe dargestellt, mit dem kleinen Unterschied, dass in der dortigen Rede zur Beschreibung der PCA die DVD-Zerlegung von [oder ] behandelt wird. statt - was einfach praktisch ist, da es sich um die PCA handelt, die über die Neuzusammenstellung der Kovarianzmatrix erfolgt. X/ √ X
—
TTNPHNS
PCA ist ein Sonderfall der SVD. PCA benötigt die Daten normalisiert, idealerweise dieselbe Einheit. Die Matrix ist in PCA nxn.
—
Orvar Korvar
@OrvarKorvar: Über welche nxn Matrix sprichst du?
—
Cbhihe