Dies sind zwei verschiedene Metriken zur Bewertung der Leistung Ihres Modells, die normalerweise in verschiedenen Phasen verwendet werden.
Verlust wird häufig im Trainingsprozess verwendet, um die "besten" Parameterwerte für Ihr Modell zu finden (z. B. Gewichte im neuronalen Netzwerk). Es ist das, was Sie versuchen, im Training zu optimieren, indem Sie die Gewichte aktualisieren.
Genauigkeit ist mehr aus einer angewandten Perspektive. Sobald Sie die oben optimierten Parameter gefunden haben, verwenden Sie diese Metriken, um zu bewerten, wie genau die Vorhersage Ihres Modells mit den tatsächlichen Daten verglichen wird.
Lassen Sie uns ein Spielzeugklassifizierungsbeispiel verwenden. Sie möchten das Geschlecht anhand des Gewichts und der Größe vorhersagen. Sie haben 3 Daten, diese lauten wie folgt: (0 steht für männlich, 1 steht für weiblich)
y1 = 0, x1_w = 50 kg, x2_h = 160 cm;
y2 = 0, x2_w = 60 kg, x2_h = 170 cm;
y3 = 1, x3_w = 55 kg, x3_h = 175 cm;
Sie verwenden ein einfaches logistisches Regressionsmodell mit y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Wie finden Sie b1 und b2? Sie definieren zuerst einen Verlust und verwenden die Optimierungsmethode, um den Verlust iterativ zu minimieren, indem Sie b1 und b2 aktualisieren.
In unserem Beispiel kann ein typischer Verlust für dieses binäre Klassifizierungsproblem sein: (Ein Minuszeichen sollte vor dem Summationszeichen hinzugefügt werden.)

Wir wissen nicht, was b1 und b2 sein sollen. Nehmen wir eine zufällige Vermutung an, sagen wir b1 = 0,1 und b2 = -0,03. Was ist dann unser Verlust jetzt?
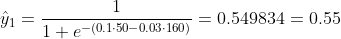
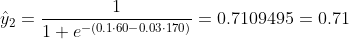
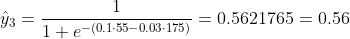
so ist der Verlust
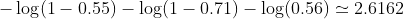
Dann wird Ihr Lernalgorithmus (z. B. Gradientenabstieg) einen Weg finden, b1 und b2 zu aktualisieren, um den Verlust zu verringern.
Was ist, wenn b1 = 0,1 und b2 = -0,03 das endgültige b1 und b2 ist (Ausgabe vom Gradientenabstieg), wie hoch ist jetzt die Genauigkeit?
Nehmen wir an, wenn y_hat> = 0,5 ist, entscheiden wir, dass unsere Vorhersage weiblich ist (1). Andernfalls wäre es 0. Daher sagt unser Algorithmus y1 = 1, y2 = 1 und y3 = 1 voraus. Wie hoch ist unsere Genauigkeit? Wir machen eine falsche Vorhersage für y1 und y2 und machen eine richtige für y3. Unsere Genauigkeit beträgt jetzt 1/3 = 33,33%
PS: In Amirs Antwort wird die Rückausbreitung als Optimierungsmethode in NN bezeichnet. Ich denke, es wäre ein Weg, um einen Gradienten für Gewichte in NN zu finden. Übliche Optimierungsmethoden in NN sind GradientDescent und Adam.
