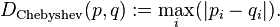Manchmal kann diese Frage nicht aufgrund der Kosten für die Durchführung von Entfernungsberechnungen auftreten, sondern aufgrund der Häufigkeit, mit der die Berechnung durchgeführt wird.
In einer großen Spielwelt mit vielen Akteuren ist es nicht skalierbar , den Abstand zwischen einem und allen anderen Akteuren zu überprüfen. Je mehr Spieler, NSCs und Projektile auf der Welt sind, desto mehr Vergleiche müssen im gleichen Maße durchgeführt werden O(N^2).
Eine Möglichkeit, dieses Wachstum zu reduzieren, besteht darin, eine gute Datenstruktur zu verwenden, um unerwünschte Akteure schnell aus den Berechnungen zu streichen.
Wir suchen nach einer Möglichkeit, alle Akteure, die sich möglicherweise in Reichweite befinden, effizient zu iterieren, wobei wir die Mehrheit der Akteure ausschließen, die definitiv außerhalb der Reichweite liegen .
Wenn Ihre Schauspieler ziemlich gleichmäßig über den Weltraum verteilt sind, sollte ein Gitter von Eimern eine geeignete Struktur sein (wie die akzeptierte Antwort nahelegt). Indem Sie Verweise auf Akteure in einem groben Raster beibehalten, müssen Sie nur einige der in der Nähe befindlichen Bereiche überprüfen, um alle Akteure abzudecken, die sich in Reichweite befinden könnten, und den Rest ignorieren. Wenn ein Schauspieler umzieht, müssen Sie ihn möglicherweise von seinem alten in einen neuen Eimer umziehen.
Für Schauspieler, die weniger gleichmäßig verteilt sind, ist ein Quadtree möglicherweise besser für eine zweidimensionale Welt geeignet , oder ein Octree ist für eine dreidimensionale Welt geeignet. Dies sind allgemeinere Strukturen, die große Bereiche des leeren Raums und kleine Bereiche mit vielen Akteuren effizient unterteilen können. Für statische Akteure gibt es eine binäre Raumpartitionierung ( Binary Space Partitioning, BSP), die sehr schnell zu suchen ist, aber viel zu teuer, um sie in Echtzeit zu aktualisieren. BSPs trennen den Raum mithilfe von Ebenen, um ihn wiederholt zu halbieren, und können auf eine beliebige Anzahl von Dimensionen angewendet werden.
Natürlich gibt es Overheads, um Ihre Akteure eine solche Struktur zu halten, besonders wenn sie sich zwischen Partitionen bewegen. Aber in einer großen Welt mit vielen Akteuren, aber kleinen Interessensbereichen, sollten die Kosten weitaus niedriger sein als diejenigen, die durch einen naiven Vergleich mit allen Objekten entstehen.
Die Überlegung, wie die Kosten eines Algorithmus steigen, wenn er mehr Daten empfängt, ist für das skalierbare Softwaredesign von entscheidender Bedeutung. Manchmal reicht es aus, einfach die richtige Datenstruktur zu wählen . Die Kosten werden normalerweise in der Big O-Notation angegeben .
(Mir ist klar, dass dies keine direkte Antwort auf die Frage ist, aber es kann für einige Leser nützlich sein. Ich entschuldige mich, wenn ich Ihre Zeit verschwendet habe!)