Ich habe eine servletbasierte Anwendung, in der ich die Zeit messe, die zum Abschließen jeder Anforderung an dieses Servlet benötigt wird. Ich berechne bereits einfache Statistiken wie den Mittelwert und das Maximum. Ich möchte jedoch eine differenziertere Analyse erstellen, und dazu muss ich diese Reaktionszeiten meines Erachtens richtig modellieren.
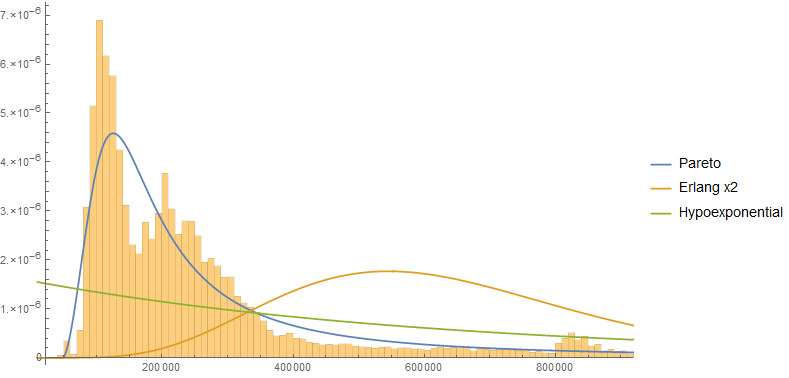
Ich sage, die Antwortzeiten folgen mit Sicherheit einer bekannten Verteilung, und es gibt gute Gründe zu der Annahme, dass die Verteilung das richtige Modell ist. Ich weiß jedoch nicht, wie diese Distribution aussehen soll.
Log-normal und Gamma kommen in den Sinn, und Sie können entweder eine Art von realen Antwortzeitdaten anpassen. Hat jemand eine Sicht auf welche Verteilung die Antwortzeiten folgen sollen?