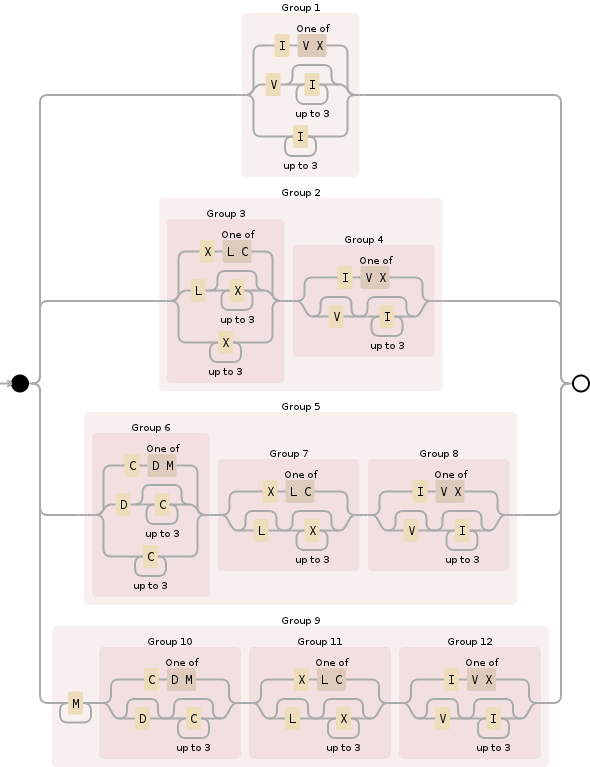
Sie können hierfür den folgenden regulären Ausdruck verwenden:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Wenn Sie es aufschlüsseln, wird M{0,4}der Abschnitt mit den Tausenden angegeben und im Grunde genommen auf zwischen 0und beschränkt 4000. Es ist relativ einfach:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Sie können natürlich M*eine beliebige Zahl (einschließlich Null) von Tausenden zulassen, wenn Sie größere Zahlen zulassen möchten.
Als nächstes ist (CM|CD|D?C{0,3})etwas komplexer, dies ist für den Hunderte-Abschnitt und deckt alle Möglichkeiten ab:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Drittens (XC|XL|L?X{0,3})folgt den gleichen Regeln wie im vorherigen Abschnitt, jedoch für die Zehnerstelle:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
Und schließlich (IX|IV|V?I{0,3})ist die Einheiten Abschnitt, Handhabung 0durch 9und auch ähnlich wie die beiden vorherigen Abschnitte (römische Ziffern, trotz ihrer scheinbaren Seltsamkeit, folgen einigen logischen Regeln , wenn Sie herausfinden , was sie sind):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Denken Sie daran, dass dieser reguläre Ausdruck auch mit einer leeren Zeichenfolge übereinstimmt. Wenn Sie dies nicht möchten (und Ihre Regex-Engine modern genug ist), können Sie positive Rückblicke und Vorausschau verwenden:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(Die andere Alternative besteht darin, vorher zu überprüfen, ob die Länge nicht Null ist).