Ich habe diese Frage seit Monaten. Es scheint, als hätten wir den Softmax nur geschickt als Ausgabefunktion erraten und dann die Eingabe in den Softmax als Log-Wahrscheinlichkeiten interpretiert. Wie Sie sagten, warum nicht einfach alle Ausgaben normalisieren, indem Sie durch ihre Summe dividieren? Die Antwort fand ich im Deep Learning-Buch von Goodfellow, Bengio und Courville (2016) in Abschnitt 6.2.2.
Nehmen wir an, unsere letzte verborgene Ebene gibt uns z als Aktivierung. Dann wird der Softmax definiert als

Sehr kurze Erklärung
Die exp in der Softmax-Funktion löscht den logarithmischen Wert des Kreuzentropieverlusts grob aus, wodurch der Verlust in z_i ungefähr linear ist. Dies führt zu einem ungefähr konstanten Gradienten, wenn das Modell falsch ist, so dass es sich schnell korrigieren kann. Ein falscher gesättigter Softmax verursacht also keinen verschwindenden Gradienten.
Kurze Erklärung
Die beliebteste Methode zum Trainieren eines neuronalen Netzwerks ist die Maximum-Likelihood-Schätzung. Wir schätzen die Parameter Theta so, dass die Wahrscheinlichkeit der Trainingsdaten (Größe m) maximiert wird. Da die Wahrscheinlichkeit des gesamten Trainingsdatensatzes ein Produkt der Wahrscheinlichkeiten jeder Stichprobe ist, ist es einfacher, die Protokollwahrscheinlichkeit des Datensatzes und damit die Summe der Protokollwahrscheinlichkeit jeder durch k indizierten Stichprobe zu maximieren :
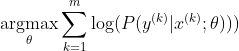
Jetzt konzentrieren wir uns hier nur auf den Softmax, wobei z bereits angegeben ist, damit wir ihn ersetzen können
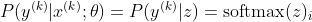
wobei i die richtige Klasse der k-ten Stichprobe ist. Wenn wir nun den Logarithmus des Softmax nehmen, um die Log-Wahrscheinlichkeit der Stichprobe zu berechnen, erhalten wir:
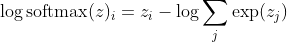
, was für große Unterschiede in z ungefähr ungefähr ist
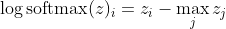
Zunächst sehen wir hier die lineare Komponente z_i. Zweitens können wir das Verhalten von max (z) für zwei Fälle untersuchen:
- Wenn das Modell korrekt ist, ist max (z) z_i. Somit asymptotisiert die logarithmische Wahrscheinlichkeit Null (dh eine Wahrscheinlichkeit von 1) mit einem wachsenden Unterschied zwischen z_i und den anderen Einträgen in z.
- Wenn das Modell falsch ist, ist max (z) ein anderes z_j> z_i. Das Hinzufügen von z_i hebt -z_j also nicht vollständig auf und die Log-Wahrscheinlichkeit ist ungefähr (z_i - z_j). Dies sagt dem Modell deutlich, was zu tun ist, um die Log-Wahrscheinlichkeit zu erhöhen: Erhöhen Sie z_i und verringern Sie z_j.
Wir sehen, dass die Gesamtprotokollwahrscheinlichkeit von Stichproben dominiert wird, bei denen das Modell falsch ist. Auch wenn das Modell wirklich falsch ist, was zu einem gesättigten Softmax führt, ist die Verlustfunktion nicht gesättigt. Es ist in z_j ungefähr linear, was bedeutet, dass wir einen ungefähr konstanten Gradienten haben. Dadurch kann sich das Modell schnell selbst korrigieren. Beachten Sie, dass dies beispielsweise beim mittleren quadratischen Fehler nicht der Fall ist.
Lange Erklärung
Wenn Ihnen der Softmax immer noch als willkürliche Wahl erscheint, können Sie sich die Rechtfertigung für die Verwendung des Sigmoid in der logistischen Regression ansehen:
Warum Sigmoidfunktion statt irgendetwas anderem?
Der Softmax ist die Verallgemeinerung des Sigmoid für Probleme mit mehreren Klassen, die analog gerechtfertigt sind.



