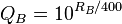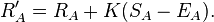Die meisten naiven Herangehensweisen an das Problem haben einige schwerwiegende Probleme. Das Schlimmste ist, wie bash.org und qdb.us Zitate anzeigen - Benutzer können ein Zitat nach oben (+1) oder unten (-1) abstimmen, und die Liste der besten Zitate wird nach der Gesamtnettowertung sortiert. Dies leidet unter einer schrecklichen zeitlichen Tendenz - ältere Zitate haben durch einfache Langlebigkeit eine große Anzahl positiver Stimmen gesammelt, auch wenn sie nur geringfügig humorvoll sind. Dieser Algorithmus könnte sinnvoll sein, wenn Witze mit zunehmendem Alter lustiger werden, aber - glauben Sie mir - nicht.
Es gibt verschiedene Versuche, dies zu beheben - Betrachtung der Anzahl positiver Stimmen pro Zeitraum, Gewichtung neuer Stimmen, Implementierung eines Zerfallsystems für ältere Stimmen, Berechnung des Verhältnisses von positiven zu negativen Stimmen usw. Die meisten leiden unter anderen Mängeln.
Die beste Lösung - denke ich - ist die, die die Websites The Funniest The Cutest , The Fairest und Best Thing verwenden - ein modifiziertes Condorcet-Abstimmungssystem :
Das System gibt jedem eine Zahl, die darauf basiert, wie viel Prozent der Dinge, mit denen es konfrontiert ist, normalerweise geschlagen werden. Jeder erhält also die prozentuale Punktzahl NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe). Außerdem werden Dinge von der Top-Liste ausgeschlossen, bis sie mit einem angemessenen Prozentsatz des Satzes verglichen wurden.
Wenn es einen Condorcet-Gewinner im Set gibt, wird diese Methode ihn finden. Da dies aufgrund des statistischen Charakters unwahrscheinlich ist, findet es denjenigen, der dem Condorcet-Gewinner am nächsten kommt.
Für weitere Informationen zur Implementierung solcher Systeme sollte die Wikipedia-Seite über Ranglistenpaare hilfreich sein.
Der Algorithmus erfordert, dass Benutzer zwei Objekte vergleichen (Ihre Auswahl-A-oder-B-Option), aber ehrlich gesagt ist das eine gute Sache. Ich glaube, dass es in der Entscheidungstheorie sehr gut akzeptiert ist, dass Menschen zwei Objekte weitaus besser vergleichen können als abstrakte Ranglisten. Millionen von Jahren der Evolution machen es uns gut, den besten Apfel vom Baum zu pflücken, aber schrecklich zu entscheiden, wie nahe der Apfel, den wir gepflückt haben, an der wahren platonischen Form der Anhaftung liegt. (Dies ist übrigens der Grund, warum der Prozess der analytischen Hierarchie so geschickt ist ... aber das kommt ein bisschen vom Thema ab.)
Ein letzter Punkt ist, dass SO einen Algorithmus verwendet, um die besten Antworten zu finden, der dem Algorithmus von bash.org sehr ähnlich ist, um das beste Zitat zu finden. Es funktioniert hier gut, scheitert dort aber furchtbar - zum großen Teil, weil eine alte, hoch bewertete, aber jetzt veraltete Antwort hier wahrscheinlich bearbeitet wird. bash.org erlaubt keine Bearbeitung, und es ist nicht klar, wie Sie jahrzehntealte Witze über jetzt datierte Internet-Memes bearbeiten würden, selbst wenn Sie könnten ... Auf jeden Fall ist mein Punkt, dass normalerweise der richtige Algorithmus hängt von den Details Ihres Problems ab. :-)