Methodenübersicht
Bei der Suche im Internet bin ich auf verschiedene Lösungen gestoßen. Ich kann sie in drei Ansätze einteilen:
- naive , die
file()PHP-Funktion verwenden;
- Betrüger , die
tailBefehle auf dem System ausführen;
- Mächtige , die glücklich mit einer geöffneten Datei herumspringen
fseek().
Am Ende habe ich fünf Lösungen ausgewählt (oder geschrieben), eine naive , eine betrügerische und drei mächtige .
- Die prägnanteste naive Lösung mit integrierten Array-Funktionen.
- Die einzig mögliche Lösung basierend auf
tail Befehlen , die ein kleines großes Problem hat: Sie wird nicht ausgeführt, wenn sie tailnicht verfügbar ist, dh unter Nicht-Unix (Windows) oder in eingeschränkten Umgebungen, in denen keine Systemfunktionen zulässig sind.
- Die Lösung, in der einzelne Bytes vom Ende der Datei gelesen werden, um nach Zeilenumbrüchen zu suchen (und diese zu zählen), finden Sie hier .
- Die Multi-Byte - gepufferten Lösung für große Dateien optimiert, fand
hier .
- Eine leicht modifizierte Version von Lösung Nr. 4, bei der die Pufferlänge dynamisch ist, wird entsprechend der Anzahl der abzurufenden Zeilen festgelegt.
Alle Lösungen funktionieren . In dem Sinne, dass sie das erwartete Ergebnis aus jeder Datei und für eine beliebige Anzahl von Zeilen zurückgeben, die wir anfordern (mit Ausnahme der Lösung Nr. 1, die bei großen Dateien die PHP-Speichergrenzen überschreiten kann und nichts zurückgibt). Aber welches ist besser?
Leistungstests
Um die Frage zu beantworten, führe ich Tests durch. So wird das gemacht, nicht wahr?
Ich habe eine Probe vorbereitet 100 KB in der verschiedene Dateien aus meinem /var/logVerzeichnis zusammengefügt wurden. Dann schrieb ich ein PHP-Skript, das jede der fünf Lösungen verwendet, um 1, 2, .., 10, 20, ... 100, 200, ..., 1000 Zeilen vom Ende der Datei abzurufen . Jeder einzelne Test wird zehnmal wiederholt (das entspricht etwa 5 × 28 × 10 = 1400 Tests), wobei die durchschnittliche verstrichene Zeit in Mikrosekunden gemessen wird .
Ich führe das Skript auf meinem lokalen Entwicklungscomputer (Xubuntu 12.04, PHP 5.3.10, Dual-Core-CPU mit 2,70 GHz, 2 GB RAM) mit dem PHP-Befehlszeileninterpreter aus. Hier sind die Ergebnisse:
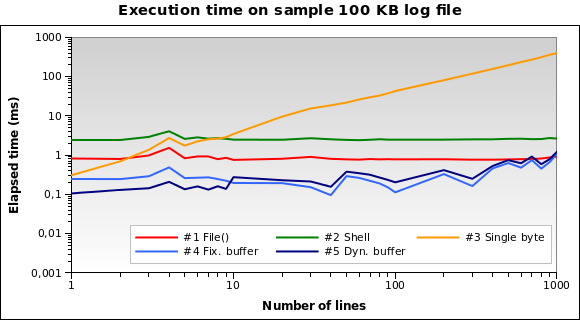
Lösung Nr. 1 und Nr. 2 scheinen die schlechteren zu sein. Lösung 3 ist nur dann gut, wenn wir einige Zeilen lesen müssen. Die Lösungen Nr. 4 und Nr. 5 scheinen die besten zu sein.
Beachten Sie, wie die dynamische Puffergröße den Algorithmus optimieren kann: Die Ausführungszeit ist aufgrund des reduzierten Puffers für einige Zeilen etwas kleiner.
Versuchen wir es mit einer größeren Datei. Was ist, wenn wir a lesen müssen? 10-MB- Protokolldatei ?
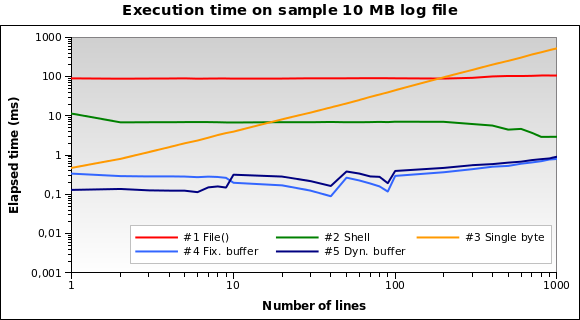
Jetzt ist Lösung Nr. 1 bei weitem die schlechtere: Tatsächlich ist das Laden der gesamten 10-MB-Datei in den Speicher keine gute Idee. Ich führe die Tests auch für 1 MB- und 100 MB-Dateien aus, und es ist praktisch die gleiche Situation.
Und für winzige Protokolldateien? Das ist die Grafik für a 10-KB- Datei:
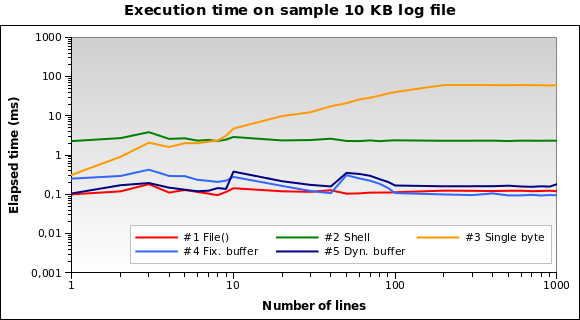
Lösung Nr. 1 ist jetzt die beste! Das Laden von 10 KB in den Speicher ist für PHP keine große Sache. Auch # 4 und # 5 schneiden gut ab. Dies ist jedoch ein Randfall: Ein 10-KB-Protokoll bedeutet ungefähr 150/200 Zeilen ...
Sie können alle meine Testdateien, Quellen und Ergebnisse hier herunterladen
.
Abschließende Gedanken
Lösung Nr. 5 wird für den allgemeinen Anwendungsfall dringend empfohlen: Funktioniert hervorragend bei jeder Dateigröße und ist besonders gut beim Lesen einiger Zeilen.
Vermeiden Lösung 1, wenn Sie Dateien lesen sollten, die größer als 10 KB sind.
Lösung Nr. 2
und Nr. 3
sind nicht die besten für jeden Test, den ich durchführe: Nr. 2 läuft nie in weniger als 2 ms, und Nr. 3 wird stark von der Anzahl der von Ihnen angeforderten Zeilen beeinflusst (funktioniert nur mit 1 oder 2 Zeilen recht gut ).
$file = file('filename.txt'); echo $file[count($file) - 1];