Es ist so ziemlich das, was du gesagt hast. Formal kann man sagen:
Varianz ist im Kontext des maschinellen Lernens eine Art von Fehler, der aufgrund der Empfindlichkeit eines Modells gegenüber kleinen Schwankungen im Trainingssatz auftritt.
Eine hohe Varianz würde dazu führen, dass ein Algorithmus das Rauschen im Trainingssatz modelliert. Dies wird am häufigsten als Überanpassung bezeichnet .
Wenn wir über Varianz beim maschinellen Lernen sprechen, beziehen wir uns auch auf Voreingenommenheit .
Bias ist im Kontext des maschinellen Lernens eine Art Fehler, der aufgrund fehlerhafter Annahmen im Lernalgorithmus auftritt.
Hohe Vorspannung bewirken würde , einen Algorithmus verpassen relevanten Beziehungen zwischen den Eingabeeigenschaften und die Zielausgänge. Dies wird manchmal als Unteranpassung bezeichnet .
Beziehung zwischen Voreingenommenheit und Varianz:
In den meisten Fällen würde der Versuch, einen dieser beiden Fehler zu minimieren, zu einer Erhöhung des anderen führen. Daher werden die beiden normalerweise als Kompromiss angesehen .

Ursache für hohe Verzerrung / Varianz in ML:
Der häufigste Faktor, der die Verzerrung / Varianz eines Modells bestimmt, ist seine Kapazität (stellen Sie sich dies als die Komplexität des Modells vor).
Modelle mit geringer Kapazität (z. B. lineare Regression) können relevante Beziehungen zwischen den Merkmalen und Zielen übersehen, was zu einer hohen Verzerrung führt. Dies ist in der linken Abbildung oben ersichtlich.
Auf der anderen Seite könnten Modelle mit hoher Kapazität (z. B. hochgradige Polynomregression, neuronale Netze mit vielen Parametern) einen Teil des Rauschens zusammen mit relevanten Beziehungen im Trainingssatz modellieren, was zu einer hohen Varianz führt, wie in der rechte Abbildung oben.
Wie kann man die Varianz in einem Modell reduzieren?
Der einfachste und gebräuchlichste Weg, die Varianz in einem ML-Modell zu reduzieren, ist die Anwendung von Techniken, die seine effektive Kapazität einschränken, dh die Regularisierung .
Die häufigsten Formen der Regularisierung sind Strafen für Parameternormen , die die Parameteraktualisierungen während der Trainingsphase einschränken. frühes Anhalten , wodurch das Training abgebrochen wird; Beschneiden für baumbasierte Algorithmen; Ausfall für neuronale Netze usw.
Kann ein Modell sowohl eine geringe Vorspannung als auch eine geringe Varianz aufweisen?
Ja . Ebenso kann ein Modell sowohl eine hohe Vorspannung als auch eine hohe Varianz aufweisen, wie in der folgenden Abbildung dargestellt.
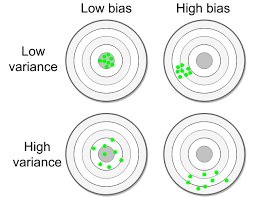
Wie können wir sowohl eine geringe Verzerrung als auch eine geringe Varianz erreichen?
In der Praxis ist die meiste Methodik:
- Wählen Sie einen Algorithmus mit einer Kapazität, die hoch genug ist, um das Problem ausreichend zu modellieren. In dieser Phase möchten wir die Verzerrung minimieren , sodass wir uns noch keine Gedanken über die Varianz machen.
- Regularisieren Sie das obige Modell, um seine Varianz zu minimieren .