Ich denke, es ist am besten, wenn ich Ihren zweiten Punkt mit einem Beispielzug in Spiel 1 zwischen AlphaZero und Stockfish erläutere, der auch meine heutige Neugier befriedigt hat.
das Zeitlimit von 1 min / Zug (Wie würde dieser Nachteil Stockfisch?)
Die Leistung von Stockfish hängt sowohl vom Zeitlimit als auch von der Hardwarekonfiguration ab. Denken Sie also daran, dass Stockfish weniger Zeit (nicht unbedingt die Hälfte) benötigt, um die Lösung zu finden, als dies bei der ersten Konfiguration der Fall wäre.
In dem ersten Bericht, der auf Chess.com veröffentlicht wurde , behauptete jemand, Stockfish spiele nicht optimal, weil er mit demselben Stockfish auf seinem Computer nicht dieselben Ergebnisse reproduzieren könne. Er sagte, dass Stockfish auf der Position unten (Spiel 1 - Zug 11) Kg1-h1 gespielt hat (seinen König bewegt hat), was überhaupt keinen Sinn ergab. Auf der anderen Seite zeigte der Stockfisch auf seinem Computer eine sich entwickelnde Bewegung wie Be3 (bewege den dunklen Läufer). Schauen wir uns die Position an:
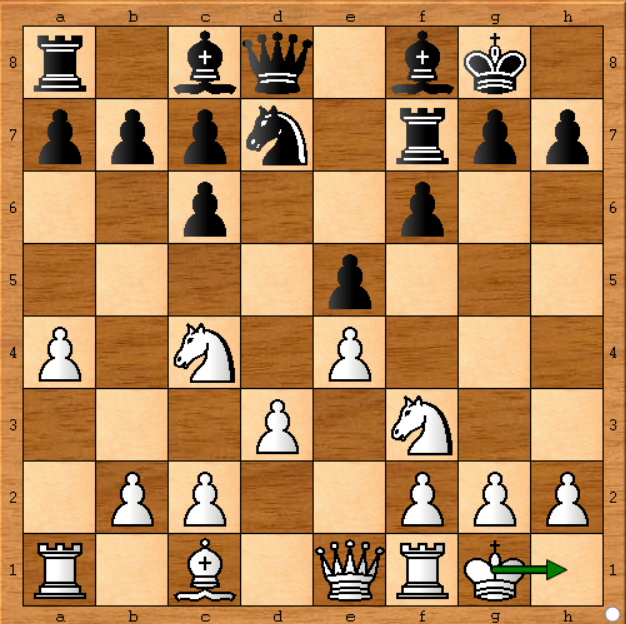
Ja, es war ein passiver Zug und es scheint, dass Stockfish einen sich entwickelnden Zug gespielt haben sollte. Aber er hat sich geirrt. Warum? Weil er 15 Sekunden mit Stockfish gefahren ist und wenn er eine Stunde gefahren wäre, hätte er Kg1-h1 als den besten Zug in dieser Position bekommen. Stockfish ändert seine Entscheidung, wenn es alle möglichen Bewegungen ausführlicher analysiert. Folgendes habe ich ursprünglich in meiner Antwort gesagt :
Ich habe den letzten Stockfisch auf der Position ausgeführt (bei Zug 11):
- Zuerst gibt es b4 als die optimale Bewegung, wenn der Motor ungefähr eine Minute lang läuft. Danach entscheidet es, dass Be3 besser ist.
Aber nach 5 Minuten auf meiner Hardware, die mit 1.400.000 Knoten / s läuft, entscheidet sie sich dafür, Kh1 als optimalen Schritt zu wählen.
In der Zeitung heißt es, dass Stockfisch 70.000.000 Positionen pro Sekunde berechnet und 1 Minute pro Zug ausgeführt wird, das ist ungefähr das 50-fache meiner Hardware, also lasse ich meine 50 Minuten laufen ... Kg1-h1 ist immer noch die Wahl für Stockfisch.
Zeitlimit ist der Schlüssel
In dem obigen Fall war es wahrscheinlich egal, ob Stockfish zweimal lief, da die Entscheidung dieselbe gewesen wäre, aber beim nächsten Schritt würde es definitiv :
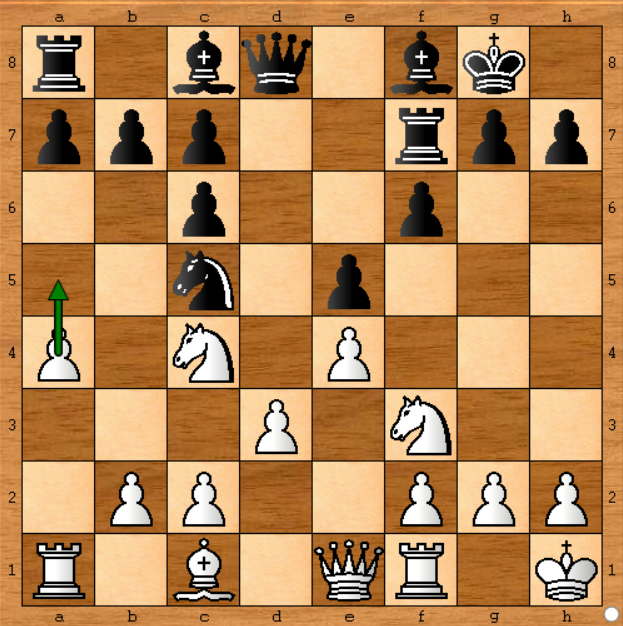
In dieser Position zog Stockfish den Bauern auf die linke Seite ( a4-a5 ). Nehmen wir an, ich habe einen Computer, auf dem die Stockfish-Engine mit einer Geschwindigkeit von 1.400.000 Knoten pro Sekunde ausgeführt wird. Dies ist ungefähr 50-mal niedriger als die Geschwindigkeit des Stockfish im realen Spiel ( in der Zeitung werden 70.000 Kn / s angegeben). So kann ich das Spiel simulieren, wenn ich es bei jedem Zug 50 Minuten lang laufen lasse. Okay.
Ich habe die Stockfisch-Analyse auf der obigen Position durchgeführt und die folgenden Ergebnisse erhalten:
- Stockfish schlug zunächst einige Züge vor, aber nach 6 Minuten auf meinem Computer (entspricht 7,2 Sekunden auf dem Stockfish im realen Spiel) zog es a4-a5 vor, genau wie das Spiel verlief .
Das ist gut, aber ich habe es 50 Minuten lang laufen lassen, um die Berechnungen des Stockfisches in dem Spiel zu erreichen, das 1 Minute lang erlaubt war:
Die traurige Wahrheit ist, dass ich glaube, dass Stockfish alle seine Spiele wegen des Zeitlimits verloren hat. Stockfisch wird im Laufe der Zeit eingehender gesucht und ausgewertet, und im Spiel durfte kein Eröffnungsbuch verwendet werden, wodurch viele Bewegungen in geringen Tiefen berücksichtigt werden. Beachten Sie, dass im aktuellen Spiel a4-a5 gespielt wurde, was zeigt, dass der Stockfisch im Spiel nicht mehr als 21,6 Sekunden unterwegs war (vorausgesetzt, er konnte 70 Millionen Positionen pro Sekunde auswerten). Andernfalls hätte es seine Entscheidung in diese drei anderen Züge im eigentlichen Spiel geändert. Der Grund dafür ist mir immer noch unklar, da mein Stockfish auch weniger Speicher verbraucht hat (ca. 130 MB RAM im Vergleich zu 1 GB im Originalpapier , vorausgesetzt, alles wird in Hash-Tabellen gespeichert ).
Fazit
Die Hardware, auf der Stockfish lief, war bestenfalls 18-mal schneller als meine (Update: auf einem einzigen Kern), basierend auf dem von mir analysierten Schritt. Ich bin mir nicht sicher, ob AlphaZero diese Hardware wirklich in 4 Stunden zum Trainieren seiner Netzwerke einsetzen kann. Ich kann nur davon ausgehen, dass sie für ein Spiel wie Schach zu niedrig ist. Außerdem hat AlphaZero diese Stunden damit verbracht, zu lernen, was auch das Bauen fester Öffnungen einschließt (und wie das Papier darauf hinweist, Vorlieben gegenüber bestimmten Öffnungen). Auf der anderen Seite war Stockfish bei Eröffnungen behindert, und es wurden nicht 60 Sekunden lang bei jeder Bewegung 70 Millionen Positionen pro Sekunde ausgewertet.
Abschließend sei angemerkt, dass alle meine Aussagen auf meinen Annahmen beruhten. Natürlich waren das Ergebnis von AlphaZero und die Spiele für mich super interessant. Ich hätte mir jedoch gerne ein Spiel angesehen, bei dem das Stockfischspiel genau so war, wie ich es auf meinem Computer erhalte. Das heißt, mehr Zeit und ein Eröffnungsbuch erlaubt. Es ist auch einfach, die Ergebnisse der Stockfish-Analyse bei jeder Bewegung abzurufen, und ich wünsche mir, dass sie veröffentlicht wird, um zu zeigen, wie gut sie funktioniert.