Ich glaube, ich werde begraben, weil ich so eine triviale Frage gestellt habe, aber ich bin etwas verwirrt über etwas.
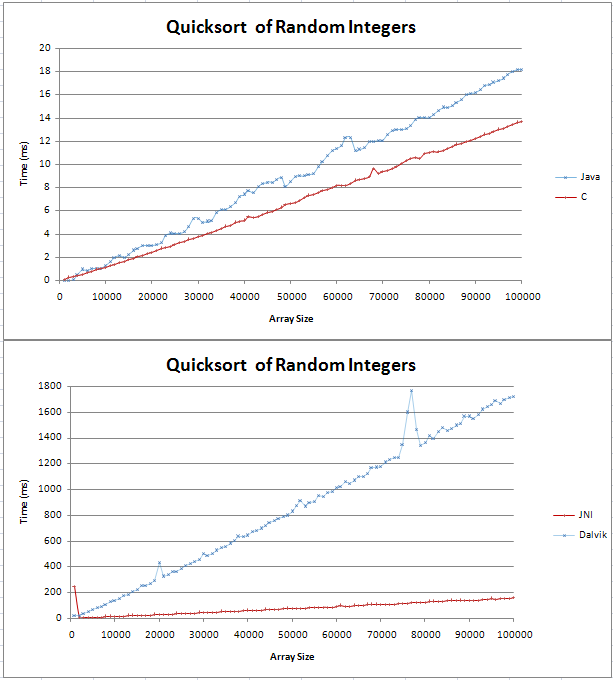
Ich habe Quicksort in Java und C implementiert und einige grundlegende Vergleiche durchgeführt. Der Graph wurde als zwei gerade Linien dargestellt, wobei das C über 100.000 zufällige Ganzzahlen 4 ms schneller war als das Java-Gegenstück.
Den Code für meine Tests finden Sie hier;
Ich war mir nicht sicher, wie eine (n log n) Linie aussehen würde, aber ich dachte nicht, dass sie gerade sein würde. Ich wollte nur überprüfen, ob dies das erwartete Ergebnis ist und ob ich nicht versuchen sollte, einen Fehler in meinem Code zu finden.
Ich habe die Formel in Excel eingefügt und für Basis 10 scheint es eine gerade Linie mit einem Knick am Anfang zu sein. Liegt das daran, dass der Unterschied zwischen log (n) und log (n + 1) linear zunimmt?
Vielen Dank,
Gav